Au sein d’une infrastructure virtualisée, l’origine d’une dégradation de performance liée, à une surcharge des ressources sur un serveur ESX, aux éléments mal dimensionnés ou provenant d’un comportement applicatif, n’est pas toujours facile à identifier.
La solution DC Scope® vous propose des méthodologies afin de mettre en évidence des problèmes de performance dans votre infrastructure et répondre au bon dimensionnement de vos machines virtuelles.
Trois cas représentatifs d’une anomalie sur la ressource processeur sont développés dans les pages suivantes. Le premier consiste à analyser le temps d’attente, de la ressource processeur d’une machine virtuelle, lié à une charge trop importante sur le serveur ESX. Il s’agit d’observer le compteur VMware « cpu ready ». Le second cas d’étude met en évidence le compteur VMware « co-stop » qui mesure le temps passé à orchestrer les « vCpu » alloués à une machine virtuelle. Pour terminer, la dernière analyse tend à montrer la défaillance d’une application et son impact sur la ressource processeur.
Le serveur ESX ne répond plus
Le compteur VMware « cpu ready » ou encore « %RDY » est utilisé pour indiquer le pourcentage de temps où la machine virtuelle est prête mais qui reste en attente afin que les instructions demandées par celle-ci soient orchestrées et exécutées sur le serveur ESX. Cette attente est due à une surcharge de la ressource processeur sur le serveur ESX.
L’analyse du compteur « cpu ready » doit être faite au niveau de la machine virtuelle mais peut aussi être réalisée au niveau du serveur ESX. Dans ce cas, il s’agit d’un cumul de ce compteur des différentes machines virtuelles qui s’exécutent sur le serveur ESX.
Pour garantir la « bonne santé » d’une machine virtuelle, la valeur du « cpu ready » ne doit pas dépasser les 5 %. L’observation de cette métrique doit être faite dans le temps pour en dégager une tendance. S’agit il d’un dépassement de seuil ponctuel, périodique ou encore de façon continue ?
Dans le premier cas, ce dépassement est probablement négligeable en revanche dans les deux autres cas, la recherche de l’origine du problème est nécessaire.
DC Scope® vous permet d’analyser les dépassements de seuils du compteur « cpu ready ».
La méthodologie ci-dessous vous permet d’identifier la surcharge processeur du serveur ESX.
- A partir de la section « Troubleshooting » de DC Scope®, nous recherchons les machines virtuelles les plus critiques sur la ressource « cpu ». En cliquant sur la machine virtuelle symbolisée par le rond rouge nous obtenons alors un « état de santé » pour chaque ressource.
NB : l’explication détaillée de la couleur et de l’inclinaison de la flèche est précisée dans la documentation DC Scope®.
- Une autre vue (« list ») permet de trier par ressource les machines virtuelles dont le nombre de points qui dépassent les seuils est le plus important.
- Cliquer sur la ressource « cpu » pour détailler les compteurs qui dépassent les seuils de bonnes pratiques.
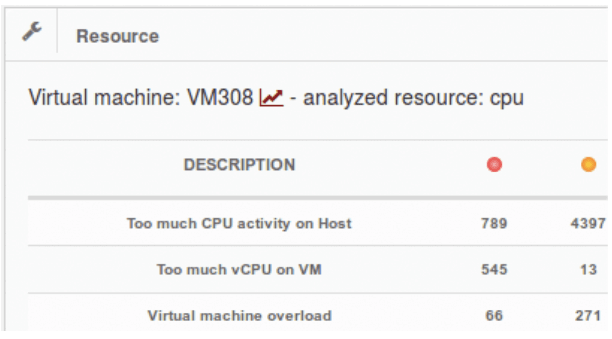
Dans ce cas d’étude, nous nous intéressons au compteur « Too much CPU activity on Host », communément appelé « TMCAOH ». Nous observons que sur la période analysée, 789 points dépassent le seuil de
10 % du compteur « TMCAOH » et 4397 points dépassent le seuil de 5 %. Le compteur « TMCAOH » est une autre représentation du compteur « cpu ready » prenant en compte l’analyse d’autres compteurs relatifs au processeur.
- En cliquant sur la valeur 789, la courbe représentant la chronologie des dépassements de seuil à 10 % s’affiche. Nous observons alors une certaine périodicité. En cliquant sur cette courbe nous nous intéressons alors aux compteurs « TMCAOH » et « cpu ready » toujours de manière chronologique.
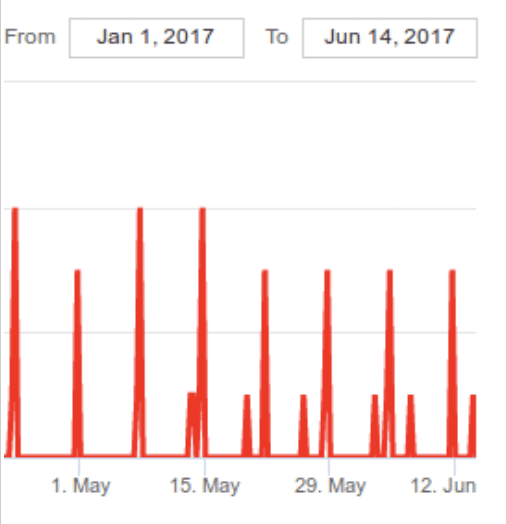
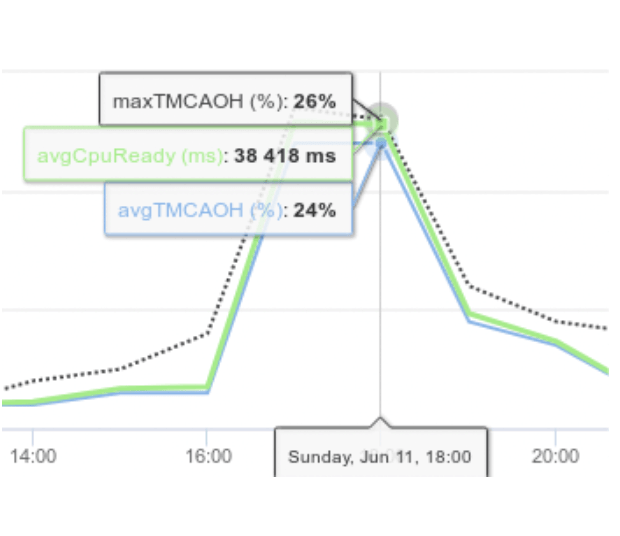
- En observant les courbes des différents compteurs, nous constatons des pics d’activité du compteur « cpu ready » à intervalle régulier. En zoomant sur le maximum de « cpu ready » observé, nous recherchons alors une date correspondant à un maximum de « cpu ready ». Dans notre exemple, il s’agit du 11 juin à 18h00 où la moyenne du compteur « TMCAOH » est de 24 % pour une valeur à ne pas dépasser de 10 %. Ces valeurs montrent que la machine virtuelle analysée (virtual machine308) doit probablement faire face à des problèmes de performance en terme de temps de réponse sur la période 16h 19h. Pour valider ce dernier point, intéressons nous aux consommations et aux propriétés du serveur (SERVER_4) sur lequel est exécutée la machine virtuelle via les rubriques « Graph On Demand » et « Server Overview » de DC Scope®.
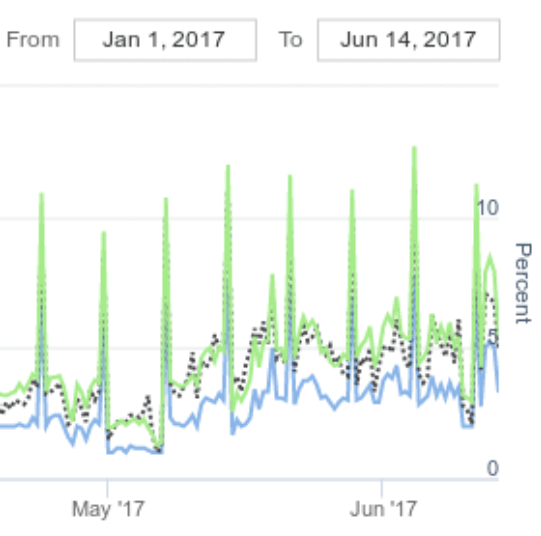
- En analysant les courbes de consommations du serveur ESX (SERVER_4), ces-dernières montrent une surcharge processeur entre 17h et 19h occasionnant les pics de « cpu ready ».
- L’analyse des propriétés du serveur (SERVER_4) montre qu’il s’agit d’une machine qui dispose de deux emplacements processeurs et que ces derniers sont déjà occupés. Par conséquent, nous ne pouvons pas préconiser d’augmenter le nombre de processeur physique dans le serveur ESX.

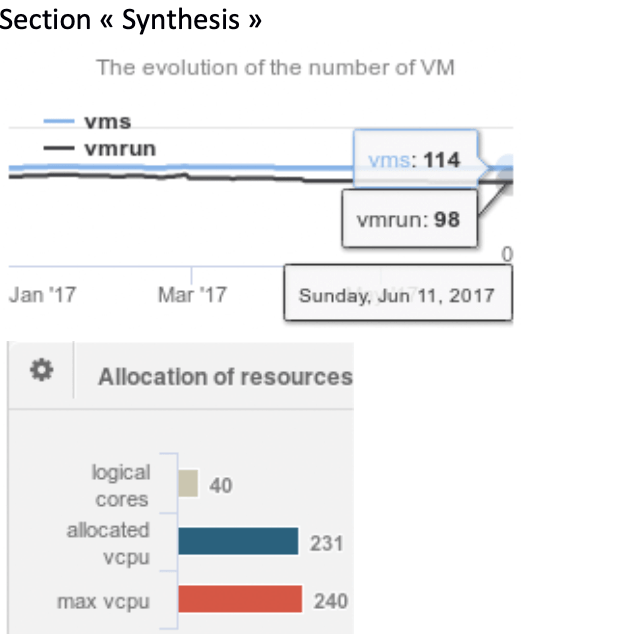
- L’analyse du nombre de machines virtuelles qui s’exécutent sur le serveur ESX, montre que 98 machines virtuelles fonctionnent pour la date du 11 juin 2017.
- De la même manière, l’analyse des allocations du nombre de « vCpu » alloués aux machines virtuelles hébergées sur le serveur ESX (SERVER_4) est de 231 soit 5,7 vCpu par cœur logique. La limite fixée sur cette allocation est de 6 vCpu par cœur.
La préconisation pour réduire le pourcentage de « cpu ready » de la virtual machine analysée (virtual machine308) passe par la réduction du nombre total de vCpu alloué aux machines virtuelles du serveur ESX ( SERVER_4).
Il y a deux approches possibles pour réduire ce paramètre. La première consiste à diminuer le nombre total de vCpu alloué aux machines virtuelles en cours de fonctionnement. La seconde consiste à diminuer le nombre de machines virtuelles qui s’exécutent sur le serveur ESX. La difficulté est de limiter le nombre de machines virtuelles qui s’exécutent notamment quand l’option VMware « DRS » est activée. Il convient alors de limiter le nombre de machines virtuelles en appliquent des contraintes de placement. - Pour réduire le nombre de total de vCpu, DC Scope® analyse le dimensionnement des machines virtuelles via la section « Recommendation ».En cliquant sur la section « VIRTUAL PROCESSORS », un tableau s’affiche alors proposant un redimensionnement par machine virtuelle en fonction de son activité réelle.
- En triant sur la colonne « VCPU » et pourcentage de « cpu ready », nous affichons les machines virtuelles dont le nombre de vCpu alloué est le plus important.
L’algorithme de DC Scope® propose alors un redimensionnement du nombre de vCpu à la hausse ou à la baisse en fonction de la consommation processeur et du pourcentage du compteur « cpu ready ».
En appliquant ces recommandations sur le nombre de vCpu alloué aux machines virtuelles, il est alors possible de réduire le cas échéant le nombre total de vCpu et donc de réduire le taux du nombre de vCpu par cœur logique.
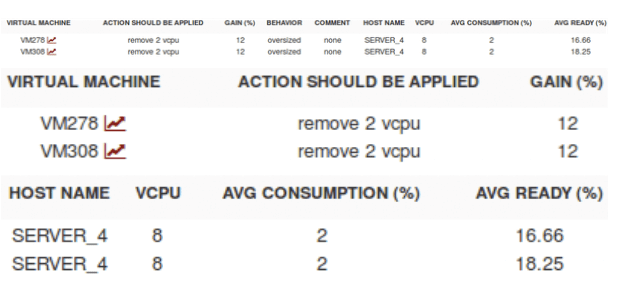
Dans le cas étudié, la machine virtual machine308 dispose de 8 vCpu générant une consommation moyenne de 2 % avec un fort taux de « cpu ready » 18%en moyenne. Ce dernier peut résulter de l’orchestration des vCpu par le serveur ESX du au grand nombre affecté à la machine virtuelle. Ce cas fait l’objet de la deuxième partie de ce document « trop de vCpu alloué et contre productivité ».
- En triant sur la colonne « VCPU » et pourcentage de « cpu ready », nous affichons les machines virtuelles dont le nombre de vCpu alloué est le plus important.
- Garder à l’esprit qu’une application tiers qui s ‘exécute à intervalle régulier sur le serveur ESX peut générer une activité qui va impacter les performances des machines virtuelles qui sont en fonctionnement, notamment des agents de sauvegarde etc …
Trop de « vCpu » alloué et contre productivité
Penser que plus on alloue de processeur à une machine virtuelle plus celle-ci sera performante est une erreur à ne pas commettre. La bonne question à se poser quand on créé une machine virtuelle et que l’on affecte le nombre de « vCpu » est de se demander ce qui va être installé comme application sur cette machine virtuelle. S’agit il d’une machine qui va héberger une base de données, un serveur web, etc …
Par ailleurs, bien souvent ,les éditeurs de solutions logicielles préconiseront d’affecter un certain nombre de « vCpu » à la machine virtuelle.
A partir de ces éléments de réponses, votre choix pour affecter le nombre de « vCpu » s’affinera avec la connaissance des programmes qui utilisent des technologies dites « multi-threading ». Par exemple, les machines virtuelles hébergeant une base de données qui gèrent en règle général le « multi-threading », se verront affecter plusieurs « vCpu ».
Garder à l’esprit qu’une machine virtuelle avec 4 « vCpu » peut avoir besoin de programmer 4 cœurs logiques pour faire une opération. Si plusieurs machines virtuelles sont configurées de cette manière, cela peut entraîner une contention au niveau processeur et une insuffisance de ressource.
Le compteur VMware « cpu costop » ou encore « %CSTP » est utilisé pour indiquer le pourcentage de temps pendant lequel la machine virtuelle est prête à exécuter des commandes, mais elle attend la disponibilité de plusieurs processeurs.
DC Scope® vous permet d’analyser les dépassements de seuils du compteur « cpu costop ».
La méthodologie ci-dessous vous permet d’identifier la contention processeur du serveur ESX.
- A partir de la section « Troubleshooting » de DC Scope®, nous recherchons les machines virtuelles les plus critiques sur la ressource « cpu ». En cliquant sur la machine virtuelle symbolisée par le rond rouge nous obtenons alors un « état de santé » pour chaque ressource.
NB : l’explication détaillée de la couleur et de l’inclinaison de la flèche est détaillée dans la documentation DC Scope®.- Une autre vue (« list ») permet de trier par ressource les machines virtuelles dont le nombre de points qui dépassent les seuils est le plus important.
- Cliquer sur la ressource « cpu » pour détailler les compteurs qui dépassent les seuils de bonnes pratiques.
Dans ce cas d’étude, nous nous intéressons au compteur « Too much vCPU on virtual machine», communément appelé « TMVOvirtual machine ». Nous observons que sur la période analysée, 2308 points dépassent le seuil de 3 % du compteur « TMVOvirtual machine » et 82 points dépassent le seuil de 1 %.
Le compteur « TMVOvirtual machine » est une autre représentation du compteur « cpu costop» prenant en compte l’analyse d’autres compteurs relatifs au processeur. - En cliquant sur la valeur 2308, la courbe représentant la chronologie des dépassements de seuil à 3 % s’affiche. Nous observons alors une certaine périodicité.
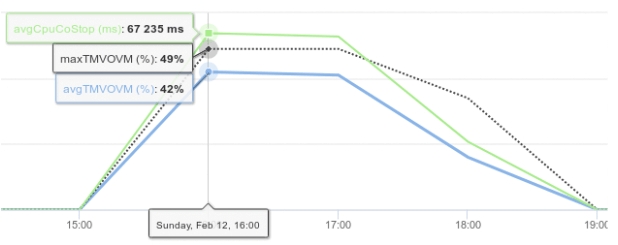
En cliquant sur cette courbe nous nous intéressons alors aux compteurs « TMVOvirtual machine » et « cpu costop» toujours de manière chronologique. - En observant les courbes des différents compteurs, nous constatons des pics d’activité du compteur « cpu costop » à intervalle régulier entre 16h et 19h et des moyennes observées à plus de 40 % sur la période incriminée. Ces valeurs montrent que la machine virtuelle analysée (virtual machine278) doit probablement faire face à des problèmes de performance en terme de temps de réponse sur la période 16h 19h.
Dans la section précédente sur l’analyse du compteur « cpu ready » il a été vérifié que la ressource cpu sur le serveur ESX est en surcharge pendant le créneau 16h 19h. La machine virtuelle virtual machine278 est exécutée sur ce serveur ESX. Il s’agit désormais de regarder le nombre de « vCpu » alloué à cette machine virtuelle. - Dans la section « virtual machine Overview » puis « Synthesis » 8 vCpu sont affectés à la machine virtuelle.
- Dans la section « Recommendation », puis en cliquant sur la section « VIRTUAL PROCESSORS », un tableau s’affiche alors proposant un redimensionnement par machine virtuelle en fonction de son activité réelle.
- En triant sur la colonne « VCPU » nous affichons les machines virtuelles dont le nombre de vCpu alloué est le plus important. L’algorithme de DC Scope® propose alors un redimensionnement du nombre de vCpu à la hausse ou à la baisse en fonction de la consommation processeur.
Dans le cas étudié, la machine virtual machine278 dispose de 8 « vCpu » générant une consommation moyenne de 1 % avec un fort taux de « cpu ready » 16% en moyenne et des pics du compteur « co-stop ». Ce dernier est amplifié par la surcharge cpu du serveur ESX et l’orchestration des 8 vCpu. - Etant donnée la consommation moyenne de la machine virtual machine278, l’algorithme DC Scope® propose de réduire le nombre de « vCpu » par palier de 2 afin de libérer des ressources sur le serveur ESX.


Applicatif qui occasionne une surcharge du processeur
Une machine virtuelle qui occasionne une activité processeur à 100% et en permanence doit faire l’objet d’une analyse pour identifier l’origine de cette surcharge. S’agit il d’une application qui ne répond plus ou encore d’un problème de démarrage de la machine virtuelle ?
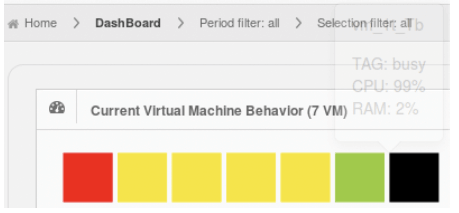
DC Scope® vous permet d’analyser ce changement de comportement via la rubrique « troubleshooting » mais aussi à partir d’un autre moyen visuel en vous connectant et en vous rendant à la section « Dashboard ». La figure ci-dessous alerte l’utilisateur sur le fait qu’une machine virtuelle occasionne une surcharge sur l’une des ressources et est représentée par un carré noir.
La méthodologie ci-dessous vous permet d’identifier une activité processeur anormale.
- A partir de la section « Troubleshooting » de DC Scope®, nous recherchons les machines virtuelles les plus critiques sur la ressource « cpu ». En cliquant sur la machine virtuelle symbolisée par le rond rouge nous obtenons alors un « état de santé » pour chaque ressource.
NB : l’explication détaillée de la couleur et de l’inclinaison de la flèche est indiquée dans la documentation DC Scope®..- 1B Une autre vue (list) permet de trier par ressource les machines virtuelles dont le nombre de points qui dépassent les seuils est le plus important.
- 1B Une autre vue (list) permet de trier par ressource les machines virtuelles dont le nombre de points qui dépassent les seuils est le plus important.
- Cliquer sur la ressource « cpu » pour détailler les compteurs qui dépassement les seuils de bonnes pratiques.
Dans ce cas d’étude, nous nous intéressons au compteur « Virtual machine overload ». Nous observons que sur la période analysée, plus de 185000 points dépassent les seuil de 90 % et 95 %. - En cliquant sur la valeur 185123, la courbe représentant la chronologie des dépassements de seuil à 95 % s’affiche. Nous observons alors une continuité des dépassements de seuil. En cliquant sur cette courbe nous nous intéressons alors aux compteurs «virtual machineO» et « cpu intra» toujours de manière chronologique.
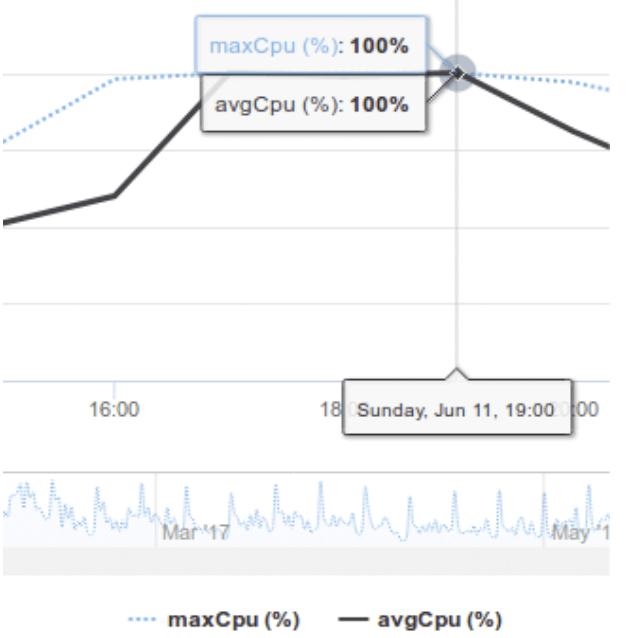
- En observant les courbes, il apparaît que la consommation moyenne à l ‘intérieure de la machine virtuelle est en permanence à 100 % ce qui n’était pas forcement le cas les jours précédents.
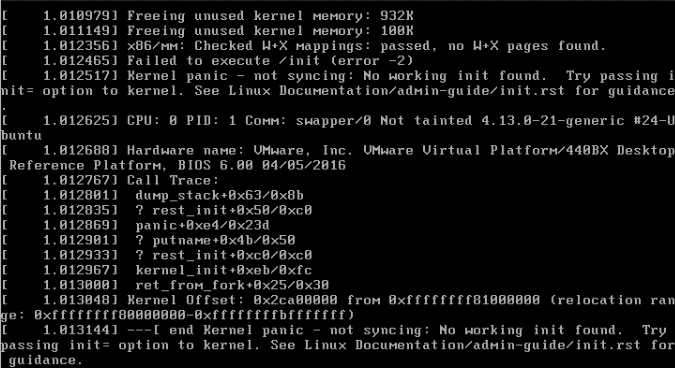
Il est nécessaire de se connecter à la machine virtuelle pour vérifier que le système d’exploitation de cette machine virtuelle a bien démarré. Si oui, il faut alors identifier le processus qui occasionne la surcharge cpu.


Exemple d’une machine virtuelle dont le système d’exploitation est endommagé et occasionnant une surcharge processeur à 100 %